
LowEndTalk作为国外最火爆的主机类社区之一,其反爬虫策略是很值得研究的。毕竟如果主机类网站本身的防护能力都一般,如何去承载如此巨大的流量,社区成员一个不开心就来一波dd/cc攻击,肯定会难以维持的。这里写一点之前的总结,如有谬误还请指正。另外本文章仅做技术分析讨论之用。
LowEndTalk使用了cloudflare的防护方案,并且是收费的企业服务,其如何做到正确识别异常请求和正常请求的呢。我们可以用无痕模式打开LowEndTalk,可以看到在这个打开过程中并没有触发cloudflare的人机验证,很流畅就直接打开了,从开发者工具中可以看到,网络请求也是直接返回了200,没有经过人机验证的跳转和识别过程。
我们知道http协议是一种无状态的协议,我们没有进行登录也不涉及到cookie对访问结果的影响,因此如果从开发者工具network中复制出https://lowendtalk.com/的请求curl,将其粘贴到命令行,原理上应该得到相同的html数据。
实际操作一下发现,不对劲啊
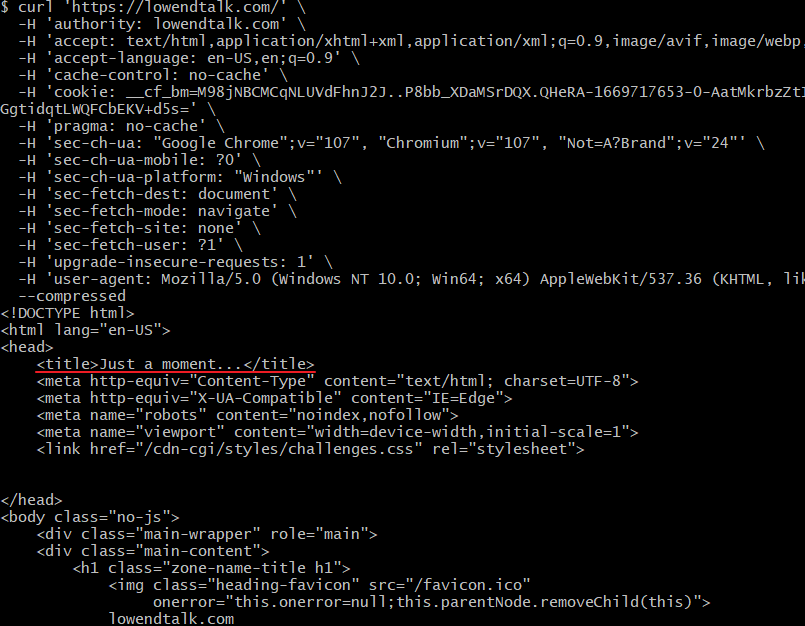
这怎么触发cloudflare的人机验证了,不应该直接返回真正的html吗,难道cloudflare是可以识别浏览器请求和curl的请求的吗。可是复制出来的curl应该能保证我们发过去的http报文一致的啊。这样如果我用其他变成语言如python/php/nodejs去爬取是不是也会得到相同的结果?使用https://curlconverter.com/可以将刚才的curl命令等价转化为其他语言的请求,这里我们选取下nodejs-axios的实现:
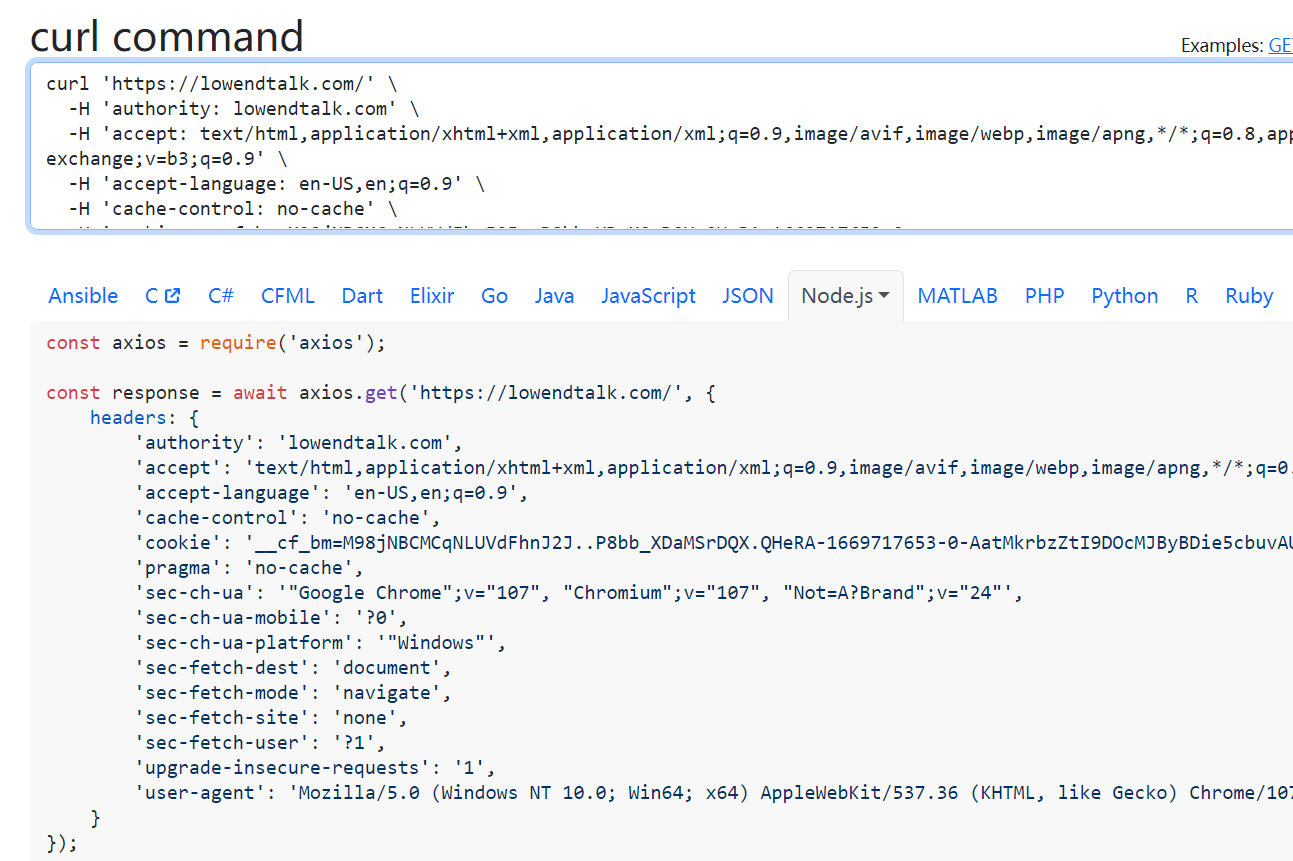
稍微改造下:
(async function (){
const axios = require('axios');
try {
const response = await axios.get('https://lowendtalk.com/', {
headers: {
'authority': 'lowendtalk.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'no-cache',
'cookie': '__cf_bm=M98jNBCMCqNLUVdFhnJ2J..P8bb_XDaMSrDQX.QHeRA-1669717653-0-AatMkrbzZtI9DOcMJByBDie5cbuvAUm5+67ZD7q8gSyVeC4vqsjLivTPZ9UFumSmLHTV4uZJGGbs0fCxWG6tnBUZkxl4BcrJh4QQzbLglGvkrWO91d4F5iaI6IGgbdCbxPgGgtidqtLWQFCbEKV+d5s=',
'pragma': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
});
} catch (error) {
console.error(error)
}
})()
运行,报错:
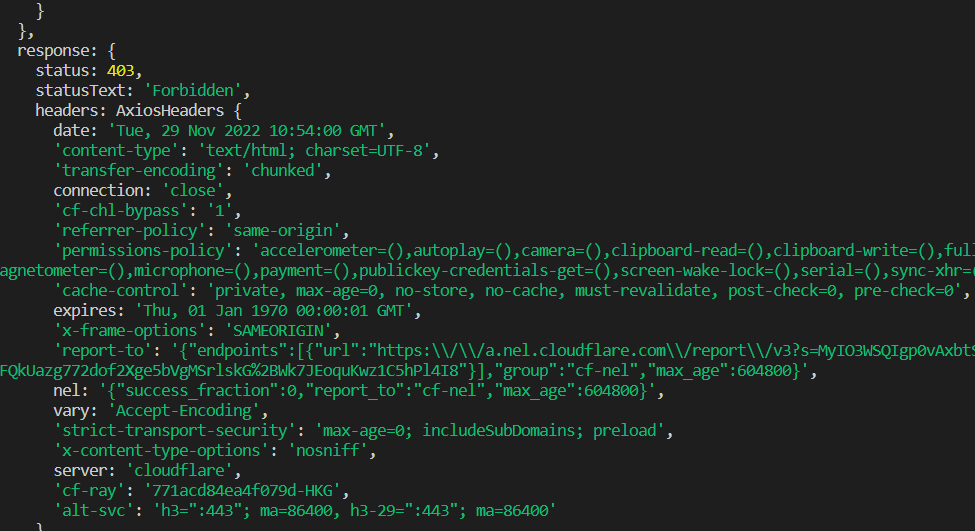
看来是经历了一样的拦截过程,那麻烦了,想要爬取let还挺费劲的。
可是为什么呢,如果不是http协议层的锅,那可能是怎么回事呢?
https,会不会是这个家伙当了叛徒,https在握手的过程中是有很多指纹信息的,比如https "Client Hello"过程中就会协商具体用什么加密算法,那么既然是要协商,就要提供自己这边支持哪些算法。这里就有个很有意思的细节,既然你要提供一个表单对吧,那么这里面的算法那些有哪些没有,哪些在前哪些在后,是没有一个统一规定的。那么不同的客户端实现就选用了不同的排列方式和算法子集,如果一个客户端比如curl或者node其排列方式有一些明显的特色,是不是可以用来区分不同的客户端呢。基于这个想法,有些研究者提出了著名的ja3指纹算法,这个算法的原理也很简单,这里不展开讲了,具体你可以去自己搜索研究下。
好了到目前为止,我们知道https中是可能存在暴露不同客户端的机制的,问题是cloudflare有采用这种机制吗。经过搜索发现,其已经将ja3指纹作为其商业反机器人的一种核心技术了!
并且也有相关的技术报道“New HTTPS Interception Tools Available from Cloudflare”
其中提到,通过这种技术大大提高了对未知流量的识别精确度,可以更好的识别出机器人。
As detailed in their blog post, the unknown status is generated when there is no "reference fingerprint for a particular browser or bot; as a result, we cannot evaluate whether HTTPS interception has occurred."
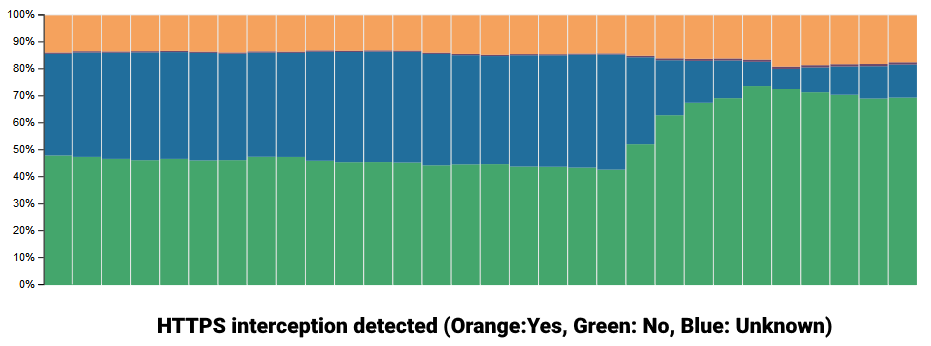
到此,我们可以推断出很有可能LowEndTalk开启了cloudflare对应的防护措施。验证的思路也很简单,只要我们能绕过tls指纹,那么就可以突破LowEndTalk官网的反爬虫策略。
如何突破。这里有个重要的逻辑点,基于tls指纹的技术很有可能会误判,因为新出的客户端其tls指纹是未加入指纹库的,一味封杀会造成非常不好的用户体验。如果把流量类型分为好的(非机器人)流量,坏的(机器人)流量,和灰色(未知指纹)流量,基于tls指纹技术的防护只会拦击典型的坏流量,而对灰色流量持宽容态度。要知道想要让nodejs准确模仿浏览器的指纹还是很难的,可是我们只需要把握手的默认包改成一个不那么常见的顺序,将其调整到灰色地带即可。有个网站提供了一个案例代码:
> require('crypto').constants.defaultCoreCipherList.split(':')
[
'TLS_AES_256_GCM_SHA384',
'TLS_CHACHA20_POLY1305_SHA256',
'TLS_AES_128_GCM_SHA256',
'ECDHE-RSA-AES128-GCM-SHA256',
'ECDHE-ECDSA-AES128-GCM-SHA256',
'ECDHE-RSA-AES256-GCM-SHA384',
'ECDHE-ECDSA-AES256-GCM-SHA384',
'DHE-RSA-AES128-GCM-SHA256',
'ECDHE-RSA-AES128-SHA256',
'DHE-RSA-AES128-SHA256',
'ECDHE-RSA-AES256-SHA384',
'DHE-RSA-AES256-SHA384',
'ECDHE-RSA-AES256-SHA256',
'DHE-RSA-AES256-SHA256',
'HIGH',
'!aNULL',
'!eNULL',
'!EXPORT',
'!DES',
'!RC4',
'!MD5',
'!PSK',
'!SRP',
'!CAMELLIA'
]
这里并没有验证这段代码的可行性,因为有很多包可以直接拿来模仿相关指纹,经过实验发现可以顺利拿到LET的数据,这也验证了上面的一系列分析。
知道了这个我们在编写爬虫程序的时候遇到类似的问题就可以绕开限制,有的朋友说那为啥不直接用基于chrome的爬虫技术如puppeteer等,那肯定是不一样的,在大规模的任务里面其效率非常低,并且对于低配服务器,其内存一般都比较吃紧,大量跑chrome显然不合理。
初次之外,tls指纹技术也可以当作我们网站的守护盾牌,比如有一些nginx扩展可以直接计算出ja3指纹,配合一定的程序处理可以精确屏蔽大部分低级爬虫,堪称降维打击。
好好好 支持
大佬